LLegué a esta charla de Drew Breunig compartida por Simon Let the LLM Write the Prompts: An Intro to DSPy in Compound Al Pipelines
Drew resume la filosofía de DSPy de la siguiente manera:
Quote
“There will be better strategies, optimizations, and models tomorrow. Don’t be dependent on any one.”
Y yo veo un gran paralelismo con el selling-point de los ORMS:
- ORM → SQL → DB
- DSPy → Prompt → LLM
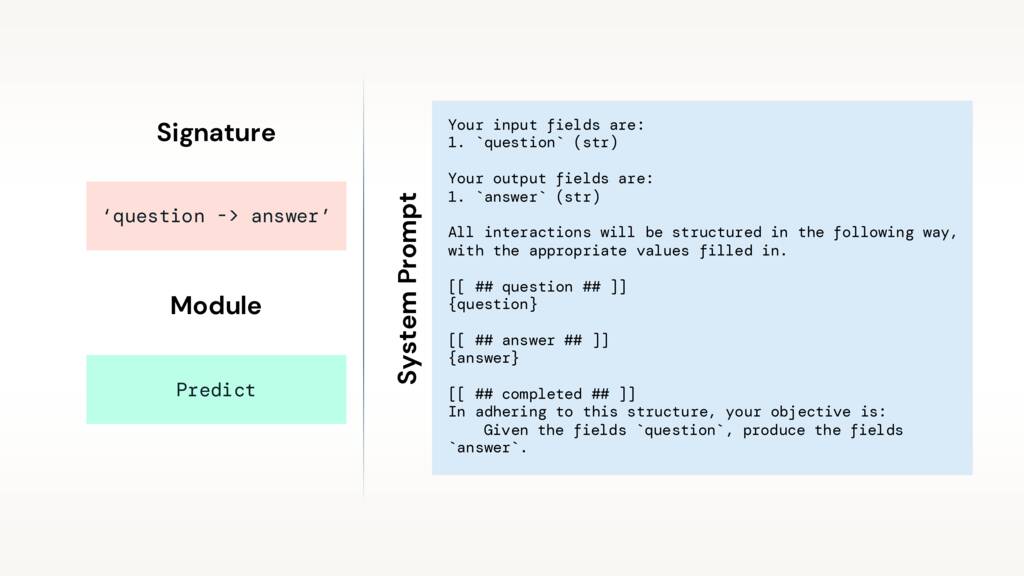
Escribí tareas, no prompts
Definis prompts en base a tareas con signatures (interfaces)
Definís modules → estrategias para buscar la info: Predict, ChainOfThought, etc
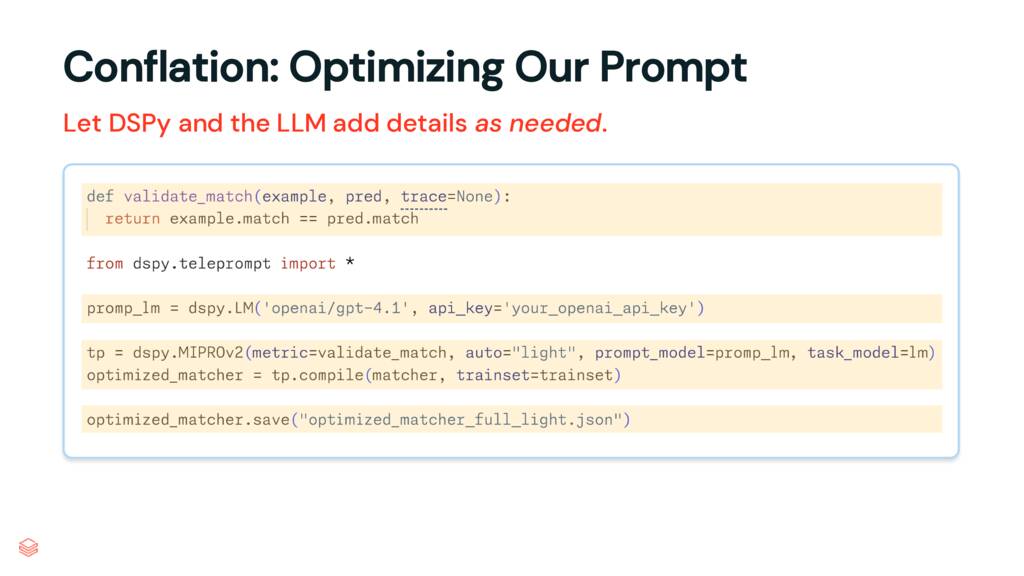
Optimiza esos prompts
- Definís una cost function o la métrica que usas para validar la respuesta
- En este caso se usan 2 modelos distintos
task_model: ejecuta la tareaprompt_model: optimiza el prompt
- Le pasas tu
trainset(labeled data) para que tenga con qué comparar - Guardas el prompt optimizado en un archivo (versioning)
Prompt 1: “Determine if two points of interest refer to the same place”
Prompt optimizado: “Given two records representing places or businesses—each with at least a name and address—analyze the information and determine if they refer to the same real-world entity. Consider minor differences such as case, diacritics, transliteration, abbreviations, or formatting as potential matches if both the name and address are otherwise strongly similar. Only output “True” if both fields are a close match; if there are significant differences in either the name or address, even if one field matches exactly, output “False”. Your decision should be robust to common variations and errors and should work across multiple languages and scripts.”
Model Portability
Además de todo esto, podes benchmarkear con distintos modelos.
ORM adecuando la sintáxis en base a la BD que usemos
